FOUNDER'S LETTER #5 Bankstatemently Open Benchmark for Bank Statement Parsing

Everybody can now build a bank statement converter. Any vision model can look at a PDF and extract transactions. So how do you know if your parser is actually good? I built a benchmark to find out.

The trust problem
If you're building anything that touches bank or credit card statements — a bookkeeping tool, a lending platform, a fraud detection system — you need test data. But real statements contain sensitive financial data. You can't share them, you can't publish them, and you definitely can't use them in a public benchmark.
So what happens? Everyone tests against their own private set of PDFs, claims "99% accuracy", and there's no way to verify any of it.
I didn't want to be another voice shouting that my parser is the best. I wanted proof. When I started building Bankstatemently, I built the evaluation system first — before the product features. Because you can't have a financial document be a little bit wrong. People are building their businesses on trusting your results.
Bank statements aren't random
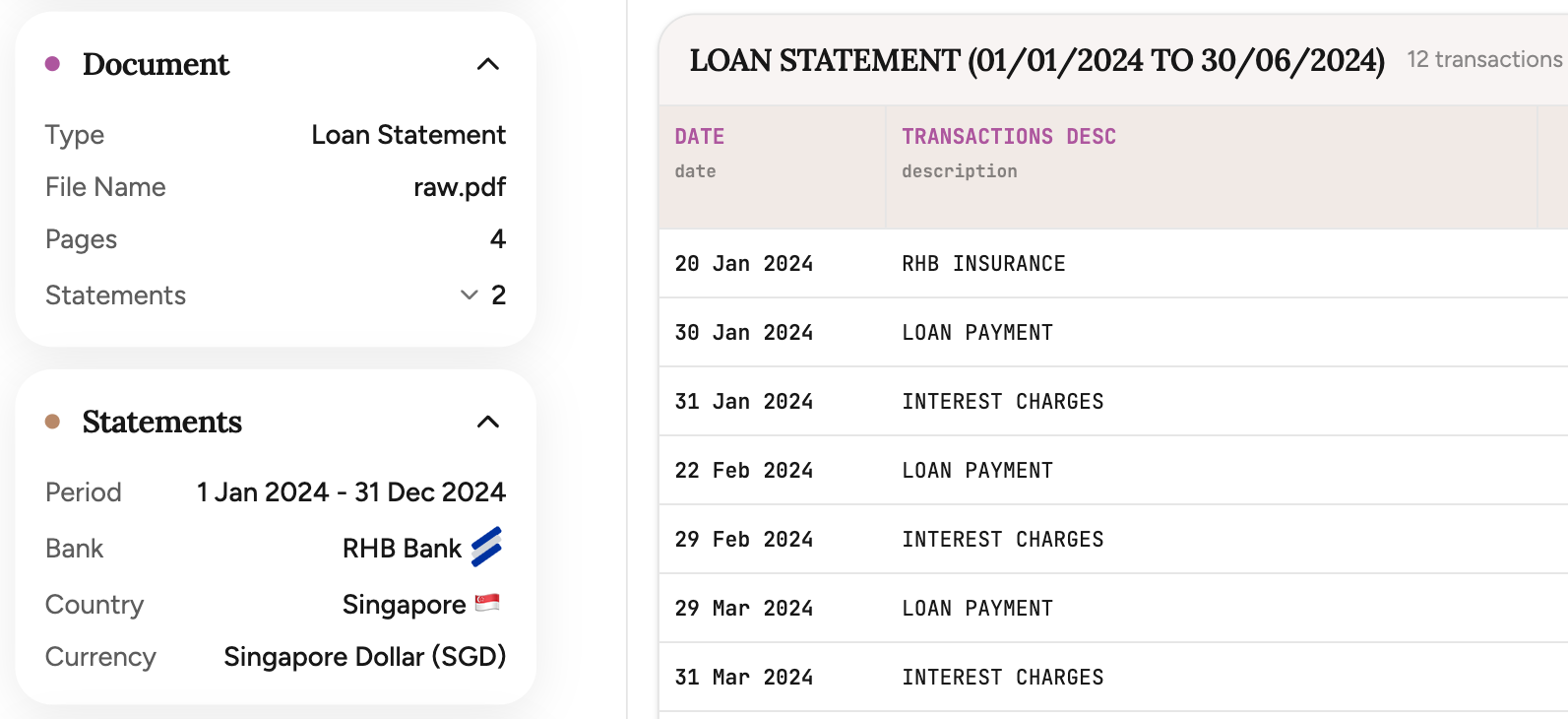
Here's an insight that might sound obvious once you hear it: bank statements can be destructured, classified, and regenerated. Every statement follows patterns — how dates are formatted, where amounts appear, how columns are laid out, how the document signals which transactions are debits and which are credits.
Once you understand these patterns deeply enough, you can generate synthetic statements that look and behave like real ones — but contain no real customer data. That's what the Bankstatemently Open Benchmark is: the end product of decomposing real bank statements into their structural components and rebuilding them from scratch.
What I'm releasing
Today I'm releasing the first 5 synthetic bank and credit card statements. 10 more are coming — and what ends up in those 10 will partly depend on your feedback.
 bsb-001 · Straits Capital (Singapore) — English, 3 pages, 12 transactions. Separate credit/debit columns, multi-line descriptions
bsb-001 · Straits Capital (Singapore) — English, 3 pages, 12 transactions. Separate credit/debit columns, multi-line descriptions bsb-002 · Liberty National (USA) — English, 4 pages, 15 transactions. Credit card with inverted signs, posting dates, non-standard page size
bsb-002 · Liberty National (USA) — English, 4 pages, 15 transactions. Credit card with inverted signs, posting dates, non-standard page size bsb-003 · Continental Trust (Netherlands) — Dutch/English, 3 pages, 22 transactions. European number formatting (comma decimals, period thousands), currency symbols in amounts
bsb-003 · Continental Trust (Netherlands) — Dutch/English, 3 pages, 22 transactions. European number formatting (comma decimals, period thousands), currency symbols in amounts bsb-004 · Silk Road Banking (Hong Kong) — English/Chinese, 4 pages, 25 transactions. Bilingual headers, multiple account tables in one document
bsb-004 · Silk Road Banking (Hong Kong) — English/Chinese, 4 pages, 25 transactions. Bilingual headers, multiple account tables in one document bsb-005 · Harbour Bank (Canada) — French, 2 pages, 25 transactions. Dates embedded in descriptions, two-digit years, space as thousands separator
bsb-005 · Harbour Bank (Canada) — French, 2 pages, 25 transactions. Dates embedded in descriptions, two-digit years, space as thousands separator
37 challenges that break parsers
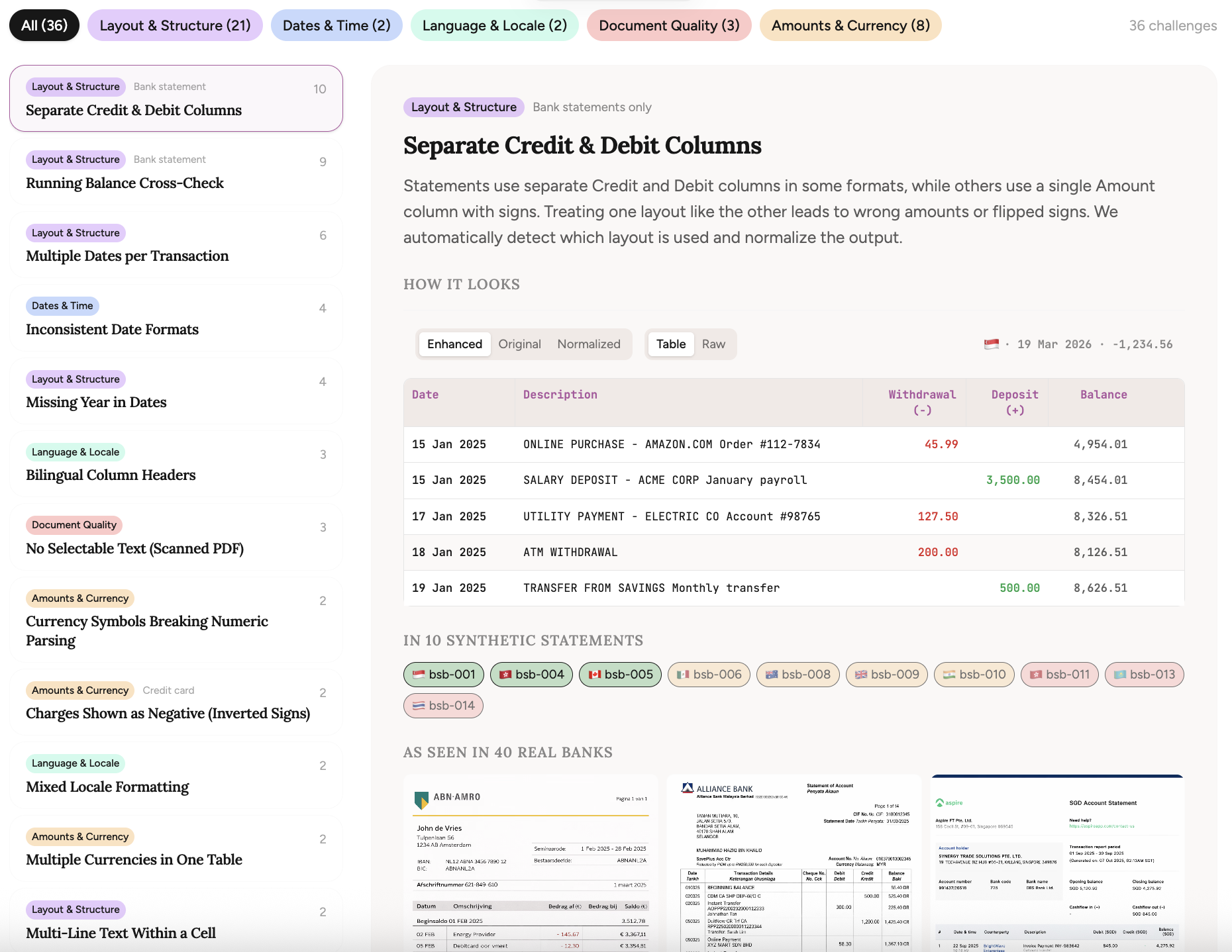
These aren't random PDFs. Each statement is deliberately crafted around real-world parsing challenges — the kind of edge cases I've encountered processing bank statements at Bankstatemently.
Dates that don't include a year. Credit card statements where charges are shown as positive numbers instead of negative. Descriptions that wrap across multiple lines. European number formatting where commas and periods swap meaning. Bilingual column headers in English and Chinese.
I've cataloged 37 of these challenges so far, organized across four categories: dates & time, amounts & currency, layout & structure, and document quality. Every challenge is documented with examples showing exactly what makes it hard.
If you know a challenge that's not in the list, tell me. I'll try to include it in the other 10 statements.
How the evaluation works
Vision models are great at understanding documents, but extraction-wise they aren't perfect. Doesn't matter how large the context window is — a hybrid between probabilistic and deterministic processing remains key. But how do you measure that?
Download the PDFs, run them through your parser, and submit the results to the free evaluation API. You get back a detailed accuracy score — field-level accuracy across dates, descriptions, amounts, and balances, plus an integrity score that checks whether transaction counts and totals are internally consistent.
The ground truth is held server-side. You submit your parsed output, and the API tells you exactly where your parser got it right and where it didn't.
Why synthetic?
Synthetic statements solve the privacy problem, but they also give something real data can't: control. Every challenge in every statement is intentional, and the dataset can be expanded with specific challenges as new edge cases are discovered in the wild.
Each statement uses a fictional bank with its own branding, format conventions, and country-specific quirks. I've taken some time to design them nicely — because the visual realism is part of the parsing challenge, and honestly, because it gave me a creative outlet beyond pure analytics.
What's next
10 more statements are in the works, covering intermediate and advanced difficulty tiers. Think scanned PDFs with OCR artifacts, multi-currency accounts, Buddhist era calendar dates, and columns where the date and month are split across separate cells.
You can already check benchmark results for commercial parsing tools — including Bankstatemently — that were evaluated using the same framework. If I'm going to ask others to be transparent about accuracy, I should go first.
The dataset is free, the evaluation API is free, and the full benchmark is open-source on GitHub. If you're building a parser, I'd love to see how it scores.
Building in public, one statement at a time.
Michael · Bankstatemently
More from the blog
How Bank Statement Analysis Improves Lending Decisions
Bank statement analysis gives lenders a current, transaction-level view of repayment capacity. Credit reports show borrowing history. Statements show whether cash actually arrives, stays, and covers the next obligation.
By Michael DuyvesteijnHow to Automate AML Bank Statement Review
AML bank statement review is evidence work. Automation helps when it extracts transactions accurately, normalizes them consistently, screens for specific risks, and preserves a clear audit trail for every alert.
By Michael DuyvesteijnLonger statements, scanned checks, and a Claude Code plugin
This month is about the statements we could not handle cleanly before. Bankstatemently now recognizes when a PDF holds several statements and converts every transaction accurately, reads the scanned checks and deposit slips that plain text leaves blank, takes files up to 50 pages (up from 20), and ships a Claude Code plugin you install in one command.
By Michael Duyvesteijn